Veja abaixo um exemplo de como podemos usar o novo tipo de campo Pesquisar e Preencher para consultar obter o Endereço de um CEP e preencher estes dados no formulário eletrônico do seu processo:
O cadastro de "Fonte de Dados" permite a criação de integrações com outros sistemas. As fontes de dados são usadas, principalmente, em dois momentos:
1. Em campos do formulário que possuem múltiplas opções para seleção (por exemplo, uma caixa de seleção com todas as Cidades da UF) ou que precisam ser preenchidas automaticamente;
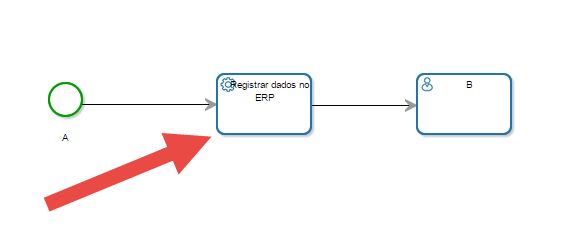
2. Em tarefas de serviço, no desenho do processo, para o envio ou captura de informações de outros sistemas;
Para que a fonte de dados possa funcionar, é necessário que seu sistema externo (seu CRM, seu ERP, seu Portal, etc.) tenha uma API. API é um conjunto de rotinas e padrões de programação para acesso a um aplicativo de software ou plataforma baseado na Web. A sigla API refere-se ao termo em inglês "Application Programming Interface" que significa em tradução para o português "Interface de Programação de Aplicativos".
Atualmente, os seguintes padrões de API´s são aceitos:
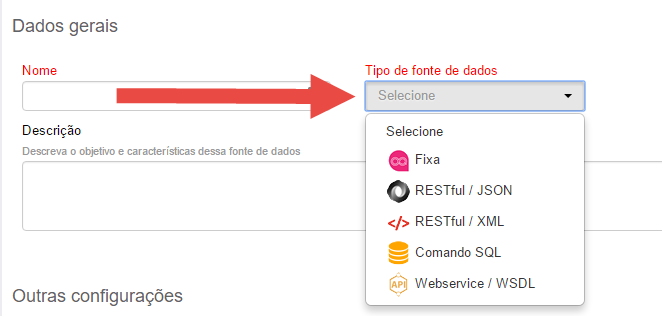
- Fixa: são dados fixos, cadastrados dentro da própria fonte de dados do Orquestra. Utilize esse tipo de integração se você não possui um sistema externo com os dados que você precisa;
- RESTful / JSON: JSON (JavaScript Object Notation) é um padrão para formato de dados bem simples, derivado da sintaxe de objetos em Javascript. E apesar de estar diretamente relacionado à JavaScript, ele é um padrão com vários parsers em diferentes linguagens, podendo servir para diferentes propósitos. Se o seu sistema externo permite conexões JSON, use esse padrão.
- RESTful / XML é a sigla para Extensible Markup Language, que significa em português "Linguagem Extensível de Marcação Genérica". É uma recomendação para gerar linguagens de marcação para necessidades especiais. XML é capaz de descrever diversos tipos de dados, e seu objetivo principal é a facilidade de compartilhamento de informações através da Internet.
- Comando SQL: "Structured Query Language", ou "Linguagem de Consulta Estruturada" ou SQL, é a linguagem de pesquisa declarativa padrão para banco de dados relacional (base de dados relacional). Esse tipo de integração permite a execução de comandos em bancos de dados externos. Apesar de geralmente a forma mais simples de integração, é a menos recomendada, devido a problemas de manutenção e organização.
- Webservice / SOAP / WSDL: WSDL é uma descrição em formato XML de um Web Service que utilizará SOAP / RPC como protocolo. É o acrônimo de Web Services Description Language (Linguagem de Descrição de Serviços Web). É um tipo de integração mais robusta e corporativa.
A decisão sobre qual padrão de integração será usada é, geralmente, definida pela forma de integração suportada pelo seu sistema externo. O Orquestra suporta os principais padrões do mercado; é possível, entretanto, que seu sistema externo suporte somente um ou outro padrão.
Governança de fonte de dados
As fontes de dados são itens muito sensíveis do sistema e erros em sua manutenção podem prejudicar diversos processos em execução. De maneira geral, recomenda-se que o cadastro de fontes de dados seja centralizado em sua equipe de processos ou equipe de TI. Faça isso controlando e restringindo o acesso a esse módulo através do cadastro de Grupos.
As fontes de dados, também, são compartilhadas por todo o sistema. Isso significa que se um usuário possui acesso ao módulo de fontes de dados, terá acesso a todas as fontes de dados do sistema. Além disso, uma vez que uma fonte de dados é criada, essa poderá ser usada em todos os processos de sua empresa.
A maior parte das configurações de fontes de dados, também, requerem um menor ou maior conhecimento técnico de linguagens de programação e de técnicas de integração de sistemas. É importante que a pessoa responsável por esse módulo conheça itens técnicos como XML, JSON, SOAP, XPATH, JSONPATH e SQL.
Configurações em comum
Para criar uma fonte de dados, vá para o menu Formulários → Fontes de dados
Alguns campos do cadastro de fontes de dados são comuns para todos os tipos de fontes dados.
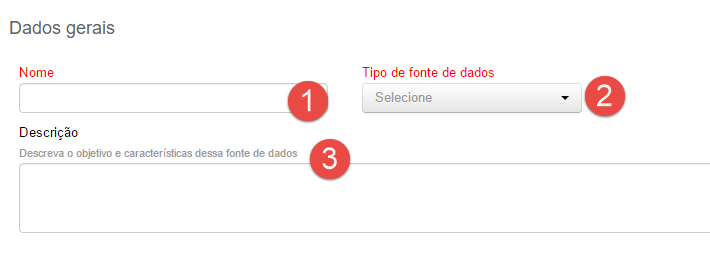
- Nome: trata-se do nome da fonte de dados. É importante que esse nome seja claro, específico e único. Esse nome será usado internamente no sistema somente. Importante: ao importar um processo de um ambiente do sistema para outro, as fontes de dados usadas pelo processo também são importadas. Nesse momento, caso o sistema encontre no ambiente de destino uma fonte de dados com o mesmo nome da nova fonte de dados sendo importada, a nova fonte de dados não será importada e o processo passará a usar a fonte de dados existente.
- Tipo de fonte de dados: refere-se a forma de integração com o outro sistema. A decisão sobre qual padrão de integração será usada é, geralmente, definida pela forma de integração suportada pelo seu sistema externo. Os demais campos do cadastro de fontes de dados irão depender da opção escolhida nesse momento;
- Descrição: é um campo de texto livre que visa documentar, somente, o funcionamento e intuito da fonte de dados. Seu uso é opcional e as informação aqui salvas são usadas internamente no sistema, somente.
Configurações específicas de conexão
Saiba como realizar as configurações específicas de cada tipo de fonte de dados
- Fixa;
- RESTful / JSON e RESTful / XML;
- Comando SQL;
- Webservice / SOAP /WSDL.
Mapeamento
Quando você executar uma conexão a uma API utilizando um dos padrões suportados, você terá como retorno um documento JSON, XML ou uma tabela de banco de dados (dependendo do tipo de fonte de dados).
Para que o Orquestra consiga compreender o documento retornado e possa efetivamente usar esses dados, você terá que configurar um processo de transformação do documento capturado para um documento JSON padrão Orquestra. Esse procedimento é realizado através da configuração do "mapeamento". Mesmo que sua API retorne um documento XML, internamente, no Orquestra, ele será transformado em JSON. Isso não tem impacto no seu uso.
É importante enfatizar que esse procedimento não é obrigatório; se você somente precisa se conectar a API para enviar dados a um sistema externo, pode ser que o retorno de informações seja irrelevante para você. Porém, se você pretende usar ou mostrar os dados retornados pela API, precisará configurar o mapeamento.
Veja o exemplo abaixo e compare o documento JSON retornado pela fonte de dados externa (a esquerda) e o documento transformado para o padrão Orquestra (a direita).
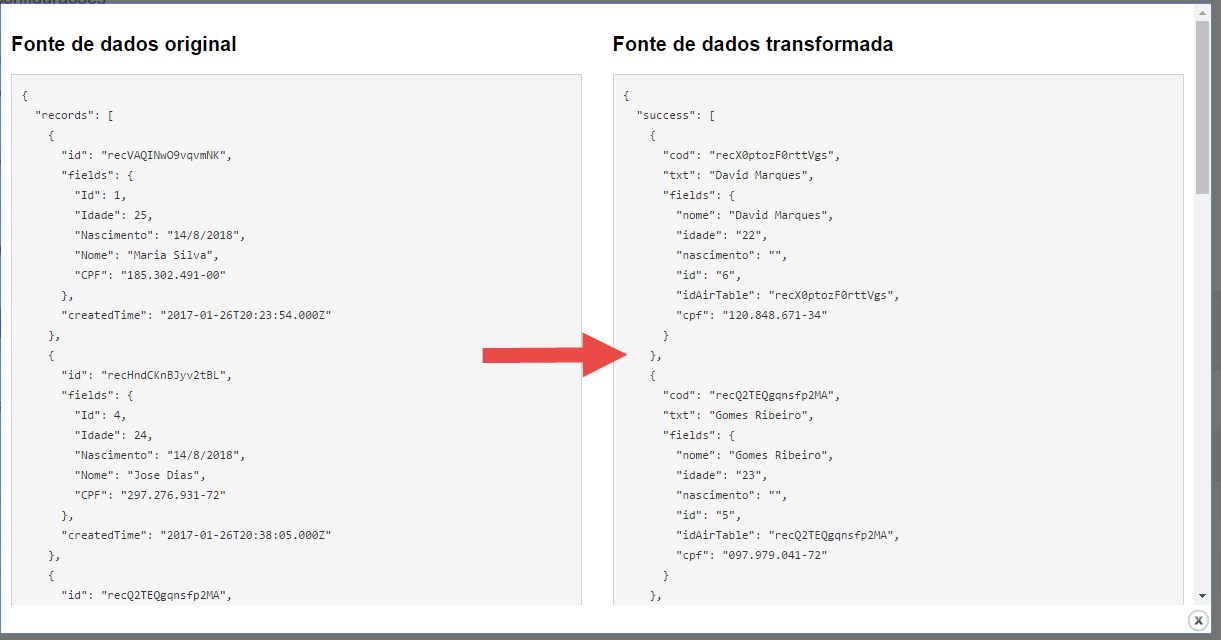
O documento JSON padrão do Orquestra tem o seguinte formato:
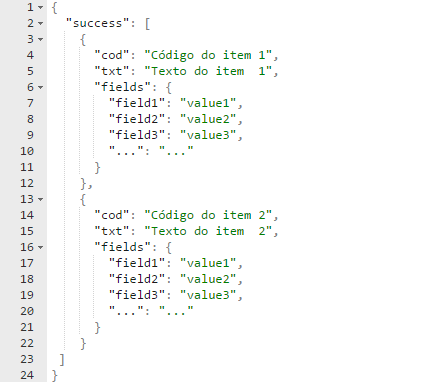
- O atributo "success" indica que a conexão com a API foi um sucesso e que o Orquestra capturou os dados do sistema externo corretamente. O atributo "success" é um vetor, isso é, ele pode armazenar diversos resultados (imagine uma tabela de banco de dados retornada; cada item do vetor "success" é uma linha da tabela);
- Para cada item retornado, temos três informações:
a. "cod": é um campo que deve armazenar um código único de identificação desse item. Se a sua fonte de dados retorna uma lista de cidades, por exemplo, esse campo armazenaria o código único de cada cidade.
b. "txt": é um campo que deve armazenar o nome ou título ou valor ou texto do item. Se a sua fonte de dados retorna uma lista de cidades, por exemplo, esse campo armazenaria o nome de cada cidade.
c. "fields": esse atributo também é um vetor e pode armazenar diversos atributos ou informações acessórias de cada item. Se a sua fonte de dados retorna uma lista de cidades, por exemplo, esse campo poderia armazenar a UF, o tamanho da população, a área total do município, etc.
Onde usar o mapeamento
As informações que você armazenar em seu documento JSON retornado pela fonte de dados poderão impactar profundamente o funcionamento de seu processo.
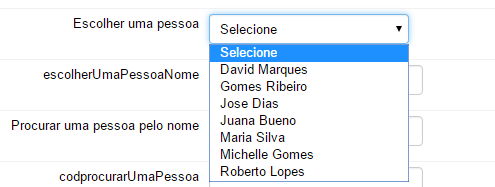
Veja a imagem abaixo, exemplificando o uso de uma fonte de dados atrelada a um campo do formulário do tipo caixa de seleção:
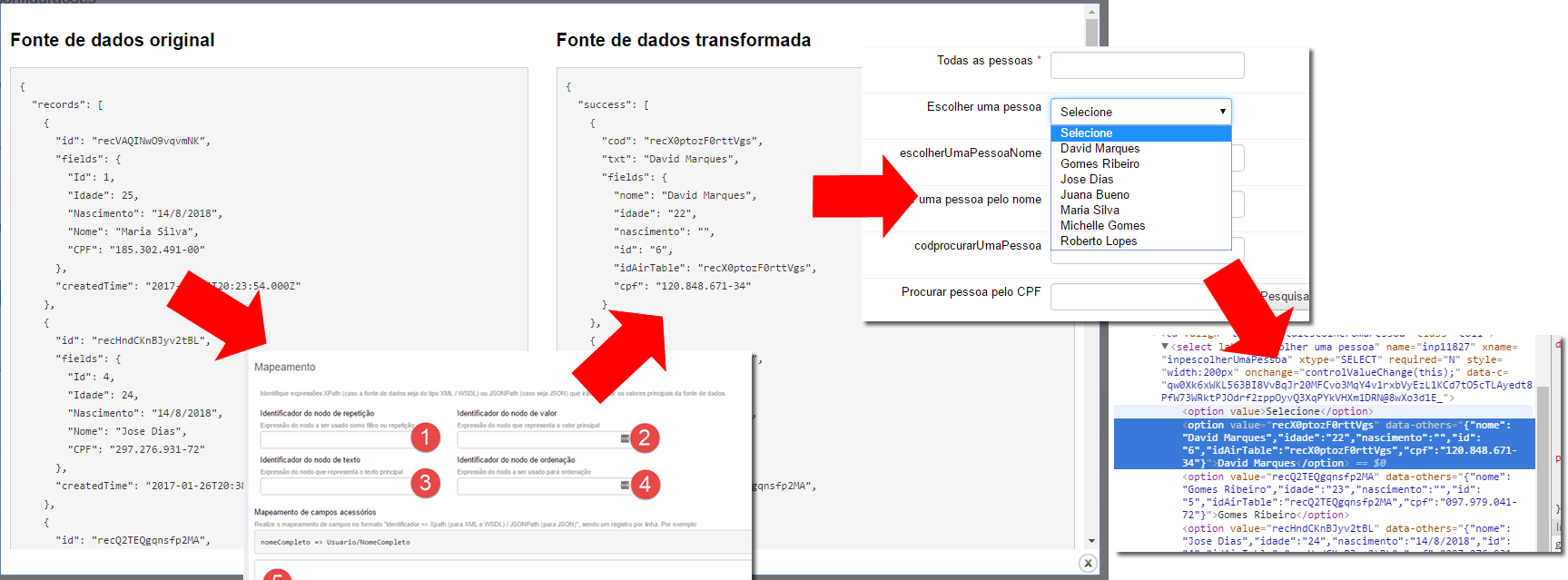
- Observe que cada item do vetor "success" da fonte de dados transformada se transforma em um item na caixa de seleção. O que o usuário vê é o valor do atributo "txt";
- Internamente, no código HTML que gera esse campo , observa-se que o atributo HTML "value" do item contém o valor do atributo "cod" da fonte de dados transformada;
- Além disso, observe que, para cada item da caixa de seleção, existe um atributo HTML customizado, chamado "data-others"; esse possui uma cópia dos campos acessórios, encontrados no vetor "fields" de cada item da fonte de dados transformada.
Como realizar o mapeamento
Observe na tabela abaixo que, mesmo com os diferentes tipos de fonte de dados, os tipos de documentos retornados resumem-se a XML e JSON. Por isso, a linguagem de transformação utilizada será XPath para documentos XML e JSONPath para documentos JSON.
| Tipo de fonte dados | Tipo de padrão usado | Linguagem para mapeamento |
|---|
| Fixa | XML | N/A |
| RESTful / JSON | JSON | JSONPath |
| RESTful / XML | XML | XPath 1.0 |
| Comando SQL | XML | N/A |
| Webservice / WSDL | XML | XPath 1.0 |
Tanto o XPath quanto o JSONPath são linguagens de navegação em documentos XML e JSON, respectivamente. O mapeamento é realizado no formulário de cadastro da fonte de dados:
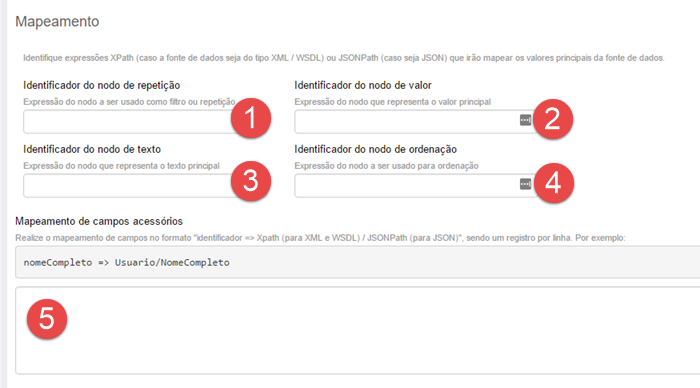
- Identificador do nodo de repetição: aqui vai o comando XPath ou JSONPath que idenficará o nodo do documento retornado pela fonte de dados que repete-se. Se a fonte de dados traz uma lista de cidades, o comando aqui indicará o nodo que indica cada nova cidade. Cada nodo identificado será um novo item no vetor "success";
- Identificador do nodo de valor: aqui vai o comando XPath ou JSONPath, relativo ao nodo de repetição, que identificará o nodo, dentro do nodo de repetição já definido, que definirá o valor do atributo "cod" da fonte de dados transformada;
- Identificador do nodo de texto: aqui vai o comando XPath ou JSONPath, relativo ao nodo de repetição, que identificará o nodo, dentro do nodo de repetição já definido, que definirá o valor do atributo "txt" da fonte de dados transformada;
- Identificador do nodo de ordenação: aqui vai o comando XPath ou JSONPath, relativo ao nodo de repetição, que identificará o nodo, dentro do nodo de repetição já definido, servirá como base para ordenação alfabética crescente dos itens do atributo "success".
Aprendendo XPath e JSONPath
Não é objetivo desse manual ensinar o uso de XPath e JSONPath. Tratam-se de linguagens padrões, altamente difundidas no mundo e com dezenas de implementações nas mais diversas tecnologias possíveis.
A título de referência, somente, e traduzido do artigo disponível em http://goessner.net/articles/JsonPath/, colocamos abaixo um exemplo comparativo entre as duas linguagens.
Também é possível validar expressões criadas utilizando o seguinte site: http://jsonpath.com/.
Considerando o documento JSON abaixo:
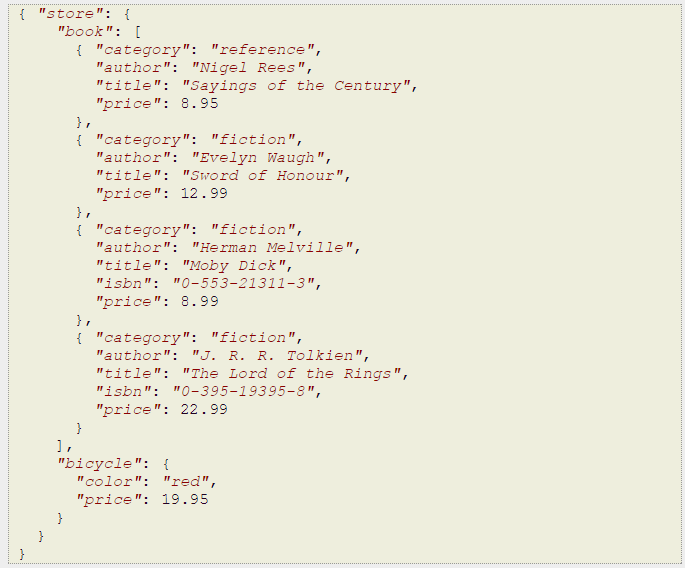
A estrutura de navegação será:
| XPath | JSONPath | Result |
|---|
| /store/book/author | $.store.book[*].author | Todos os autores de livros |
| //author | $..author | Todos os autores |
| /store/* | $.store.* | Todos os produtos da loja |
| /store//price | $.store..price | Todos os preços da loja |
| //book[3] | $..book[2] | O terceiro livro |
| //book[last()] | $..book[(@.length-1)]
$..book[-1:] | O último livro |
| //book[position()<3] | $..book[0,1]
$..book[:2] | Os primeiros 2 livros |
| //book[isbn] | $..book[?(@.isbn)] | Todos os livros com isbn |
| //book[price<10] | $..book[?(@.price<10)] | Todos os livros mais baratos do que 10 |
| //* | $..* | Todos os elementos |
A tabela abaixo traz uma comparação da sintaxe das duas linguagens:
| XPath | JSONPath | Description |
|---|
| // | $ | O elemento raiz do documento |
| . | @ | O elemento atual |
| / | . or [] | Navegar para elemento filho |
| .. | n/a | Navegar para elemento pai |
| * | * | Todos os elementos, independentes do tipo |
| @ | n/a | Filtrar um atributo |
Exemplo de mapeamento com documento XML
Considere o documento XML abaixo:
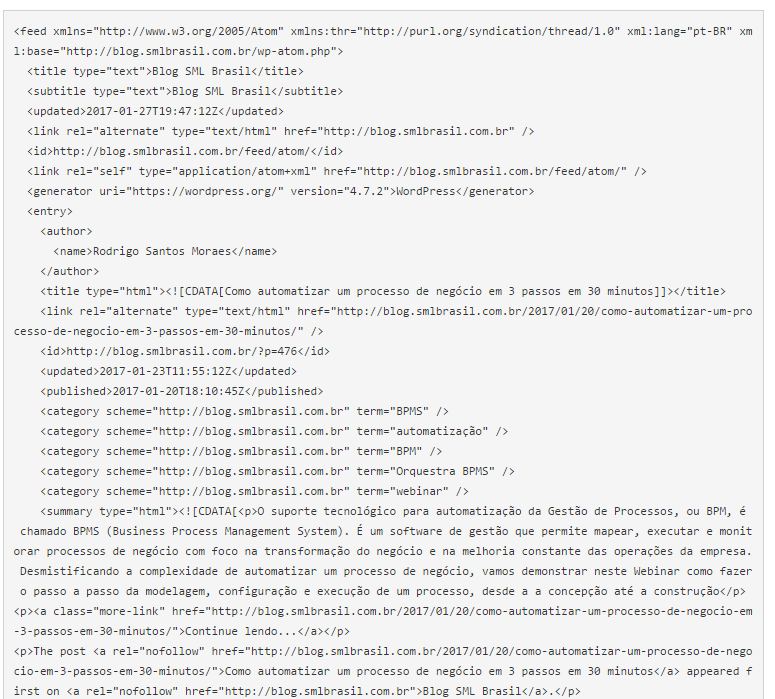
Trata-se de um feed de notícias de blog. Veja abaixo como o mapeamento poderia ser definido:
| Identificador | Mapeamento |
|---|
| Identificador do nodo de repetição | //feed/entry ou simplesmente entry |
| Identificador do nodo de valor | id |
| Identificador do nodo de texto | title |
| Identificador do nodo de ordenação | title |
Observe que o identificador do nome de repetição pode ser a expressão XPath completa "//feed/entry" ou simplesmente o nome do nó de repetição, "entry". Isso pois, no caso exclusivo desse nodo, o Orquestra, caso não identifique a expressão de busca como XPath, irá simplesmente realizar uma busca simples pelo nome do nodo no documento.
Os demais identificadores, apesar de não parecer, são expressões XPath. Nesse caso, a expressão XPath dos nodos de valor, texto e ordenação é relativa ao nodo de repetição. Como são filhos diretos do nodo de repetição, a expressão XPath relativa é o próprio nome do nodo.
Exemplo de mapeamento com documento JSON
Considere o seguinte documento de exemplo JSON:

Veja abaixo como o mapeamento poderia ser definido:
| Identificador | Mapeamento |
|---|
| Identificador do nodo de repetição | $.records |
| Identificador do nodo de valor | id |
| Identificador do nodo de texto | fields.Nome |
| Identificador do nodo de ordenação | fields.Nome |
Ao contrário de documentos XML, onde o identificador do nodo de repetição pode ser simplesmente o nome do nodo, no caso de documentos JSON, deve ser uma expressão JSONPath completa. Por isso, o identificador de repetição é $.records, sendo que $ representa o início do documento e "records" o nome do vetor que contém os itens de repetição.
As demais expressões são relativas ao nodo de repetição. Por tanto, a expressão para capturar o campo "id" é simplesmente o próprio nome do nodo, já que esse é filho direto do item de repetição. Já o nome está em uma estrutura inferior, e a navegação se dá pela expressão "fields.Nome".
Concatenando expressões
É possível concatenar expressões XPATH ou JSONPath, formando assim expressões ou valores mais complexos. Para isso, utilize o operador "+". Para concatenar com textos fixos, utilize aspas simples. Por exemplo, a string abaixo concatena diversos comandos XPATH para formar um endereço completo:
end + ' ' + complemento + ' ' + complemento2 + ', ' + bairro + ', ' + cidade + ', ' + uf + ', Brasil'
Lembrando que deve-se sempre utilizar aspas simples (') para representar valores fixos, caso contrário poderão ocorrer erros de leitura do caminho
Mapeamento de campos acessórios
O mapeamento de campos acessórios permite definir uma série de expressões XPATH ou JSONPath adicionais, acessórias e opcionais para a fonte de dados. Na fonte de dados transformada, essas expressões são convertidas em atributos do vetor "fields".
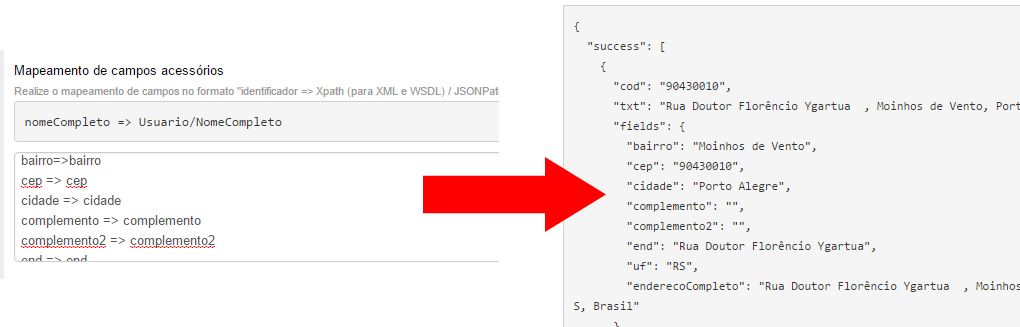
A configuração do mapeamento acessório é feita com a seguinte expressão abaixo, uma por linha:
identificador do atributo => expressão XPATH ou JSONPath relativa ao nodo de repetição.
O "identificador do atributo" é o nome escolhido por você e será mostrado na fonte de dados transformada.
O mapeamento de campos acessórios é usado principalmente para dois fins:
- Em campos do formulário do tipo "caixa de seleção", "sugestão" ou "pesquisar e preencher", caso os identificadores da fonte de dados transformada sejam iguais aos identificadores de outros campos do formulário. Nesse cenário, esses campos terão seus valores automaticamente preenchidos uma vez selecionado o valor principal do campo origem. Exemplo: digamos que você tenha uma fonte de dados de pessoas cujo atributo "id" é o identificador único da pessoa, e o atributo "txt" é o nome da pessoa. O vetor "fields" poderia ter uma série de atributos adicionais com outras informações da pessoa, como "email", "cpf" e "sobrenome". Se você vincular essa fonte de dados a um campo caixa de seleção, o usuário poderá ver e escolher um dos nomes de pessoas disponíveis. Quando o usuário escolher uma pessoa, caso existam campos nesse formulário com identificadores "email", "cpf" e "sobrenome", esses campos serão automaticamente preenchidos com as informações da fonte de dados transformada.
- Na execução de tarefas de serviço, configurada no desenho do processo. Nesse cenário, quando a tarefa de serviço for executada, caso existam campos no formulário com identificadores iguais a atributos do vetor "fields", esses campos terão seus valores automaticamente atualizados conforme o valor do atributo na fonte de dados transformada. Utilize esse recurso para atualizar o valor de um ou mais campos do formulário a partir de uma consulta ou processamento a um serviço externo.
Todo documento JSON de uma fonte de dados transformada trará ao final importantes atributos.
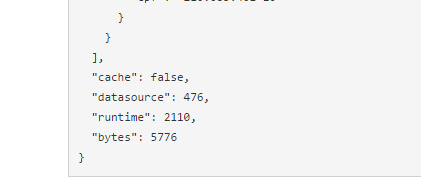
- Cache: indica se os dados dessa consulta foram recuperados através de um cache (cópia) dos dados, ou se efetivamente foi realizada a integração com o sistema externo. Veja mais sobre cache nos próximos capítulos.
- Datasource: indica o ID único de identificação dessa fonte de dados;
- Runtime: indica o tempo, em milisegundos, que o sistema levou para conectar, enviar dados e recuperar dados da fonte de dados externa. Quanto maior esse tempo, pior será a experiência do usuário. Um valor acima de 2000 é considerado alto e pode ser prejudicial. Caso esse valor esteja muito alto, verifique:
a. A performance do sistema externo;
b. O tempo de resposta do sistema externo;
c. Eventuais bloqueios ou dificuldades de conexão de redes;
4. Bytes: indica o total de bytes retornados pelo sistema externo. Quanto maior esse número, pior será a experiência do usuário e mais lenta será a consulta. Caso esse valor esteja muito alto, verifique maneiras de o sistema externo retornar somente as informações essenciais para execução da operação.
Outras configurações
Ao final do formulário de cadastro de fontes de dados, outras configurações são utilizadas por diferentes tipos de fontes de dados:

- Configuração de nulidade: Essa configuração somente é usada se a configuração da sua fonte de dados é dependente de variáveis de qualquer tipo, como informações do usuário logado, da instância de processo em execução ou mesmo dos valores de campos do formulário. Até a versão 3.6.2 do sistema, todas as fontes de dados existentes possuíam somente uma configuração de nulidade: "Substituir token por vazio e executar a consulta". A partir da versão 3.6.3, você pode escolher entre essa opção legada e uma nova opção padrão, "Não executar a consulta"
a. Substituir token por vazio e executar a consulta: imagine que você tem uma fonte de dados que lista todas as cidades de um determinada UF. A configuração de sua fonte de dados, portanto, deverá, de alguma forma, receber obrigatoriamente a informação de qual UF você deseja listar as cidades. Você faz isso usando algum tipo de token na configuração de sua fonte de dados. Ao selecionar essa opção, caso você ainda não possua a informação da UF, a consulta da lista de cidades ainda assim será realizada, considerando as cidades cuja UF seja vazia. Provavelmente, a lista virá simplesmente vazia. Em outros casos, você poderá realizar um tratamento em sua fonte de dados para que, se a UF é vazia, retornar alguma outra informação.
b. Não executar a consulta: esse é o novo valor padrão de fontes de dados e a configuração recomendada. Seguindo o mesmo exemplo anterior, nesse caso, a consulta nem mesmo será executada caso alguma informação necessária seja vazia. Isso economiza processamento do sistema, na maioria das vezes.
Durante a atualização de seu sistema da versão 3.6.2 para 3.6.3, todas as suas fontes de dados legadas foram fixadas no antigo valor default, "Substituir token por vazio e executar a consulta", de modo a não ocorrer nenhum problema de compatibilidade.
2. Cache: essa configuração é fundamental, notadamente se essa fonte de dados será usada para listar itens de uma fonte de dados externa (exemplo: listar todos centros de custos da empresa a partir de uma consulta ao ERP). Nesse campo você digitará um valor decimal (exemplo: "0,5", "1", "1,5") representando o tempo, em horas, que o sistema armazenará em cache a consulta realizada. Durante o período de cache, o sistema não executará mais consulta à fonte de dados externa pois terá armazenado uma cópia local dos dados. Isso ajuda a economizar recursos do sistema principalmente nos cenários onde a sua lista de dados não muda ou muda muito pouco. Por exemplo, uma lista de cidades com certeza deve ter um valor de cache alto, pois essa lista muda esporadicamente. Por outro lado, é possível que uma lista de chamados abertos recentemente no help desk não deva ter cache pois você quer visualizar os últimos chamados abertos.
3. Identificador do nodo de erro: essa configuração é usada se você faz uso de uma fonte de dados do tipo JSON, XML ou WSDL. Ela permite que o sistema identifique que o retorno do sistema externo foi um erro, e não um sucesso. Isso é muito importante e o não uso ou uso errado desse recurso pode ter impactos negativos no sistema. Você deve informar, nesse campo, a expressão XPATH ou JSONPath que, se encontrada, indicará ao sistema que ocorreu um erro no sistema externo. Nesse cenário, a fonte de dados transformada não trará mais o documento de sucesso, e sim um alternativo, de erro.
Importante: o sistema identifica automaticamente mensagens de erro no padrão SOAP-Fault 1.0, no caso de integrações via SOAP / Webservices (https://technet.microsoft.com/pt-br/library/ms189538(v=sql.105).aspx). Nesse caso, a configuração do nodo de erro é opcional.
Importante: caso você esteja usando a fonte de dados em uma tarefa de serviço no desenho do processo e não tenha configurado um padrão de identificação de erros, corre o risco de instâncias de processos serem executadas, ocorrer erro na integração, e mesmo assim a execução do processo continuar. Isso pode gerar inconsistências e problemas em processos.
4. Identificador do nodo de erro amigável: caso o padrão de documento de erro de seu sistema externo possua uma tag ou um atributo que traga uma mensagem de erro amigável, passível de ser mostrada ao usuário, cadastre aqui a expressão XPATH ou JSONPath, relativa a expressão de nodo de erro anterior. É importante que essa seja uma mensagem amigável, com uma instrução ao usuário, preferencialmente na língua do usuário. Caso seu sistema externo não retorne uma mensagem de erro amigável, deixe esse campo em branco. Importante: o padrão SOAP-Fault comentado acima é, por natureza, para erros técnicos, e não erros amigáveis. Erros técnicos são erros internos de processamento não tratados pelo seu sistema externo. É um erro usar o padrão de mensagens SOAP-Fault para mostrar mensagens amigáveis.
5. Permitir o uso em processos com usuário anônimo: essa é uma mudança importante do sistema da versão 3.6.2 para 3.6.3. Em versões mais antigas do sistema todas as fontes de dados podiam ser usadas, sem restrições, em processo anônimos, onde não temos um usuário identificado. Por questões de segurança, a partir da versão 3.6.3, essa opção vem desabilitada. Caso você queira usar essa fonte de dados em um ambiente não autenticado, deve marcar essa opção. Durante a migração do sistema da versão 3.6.2 para 3.6.3, todas as fontes de dados já existentes foram automaticamente marcadas para permitir o uso em processos anônimo, fixando o comportamento antigo e evitando problemas de compatibilidade.
Testar fonte de dados
Uma vez criada a fonte de dados, você poderá selecionar uma das opções de teste disponíveis ao final do formulário de cadastro da fonte de dados. A fonte de dados original, captada do sistema externo, conjuntamente com a fonte de dados transformada, após o processo de mapeamento, será mostrada.
Compartilhar e integrar
A caixa de "compartilhar e integrar" traz duas strings de integração dessa fonte de dados com outros sistemas.
A primeira é um link HTTP que leva diretamente para a tela de processamento da fonte de dados, mostrando o documento JSON da fonte de dados transformada. Esse link pode ser usado:
- Por outros sistemas, externos ao Orquestra, que queiram se integrar ao Orquestra ou buscar informações dessa fonte de dados;
Para isso, é necessário que o campo "Permitir o uso em processos com usuário anônimo" esteja habilitado, e o usuário anônimo devidamente configurado. Nessa modalidade, o acesso a fonte de dados não é autenticado.
- Saiba como Configurar Acesso Anônimo.
- Por customizações Javascript, envolvendo chamadas AJAX complexas em customizações do formulário;
Esse link disponibilizado, a priori, não muda entre diferentes instalações do Orquestra, permitindo que você utilize ele hard-coded em suas customizações. As exceções são:
- A raiz do link, que traz o endereço do servidor (por exemplo, abaixo temos o link começando por http//localhost:91, sendo que o endereço de produção poderia ser outro, como http://orquestra/);
- Ambientes que usem padrões de criptografia diferentes;
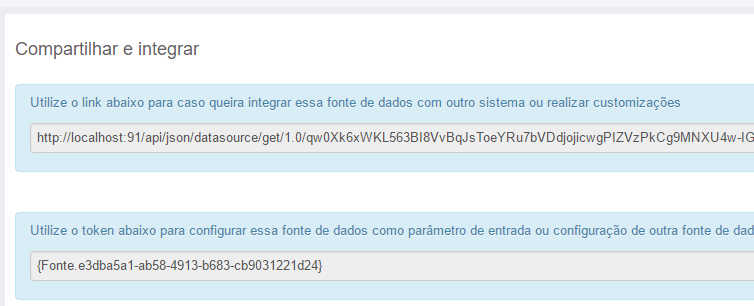
A segunda informação disponibiliza é o token para acesso direto a informação dessa fonte de dados. O token pode ser usado em todos os demais locais do sistema onde tokens são permitidos. Inclusive como parâmetro de configuração de outras fontes de dados. Nesse caso, o sistema irá retornar somente o valor do atributo "cod" da fonte de dados transformada. Caso a fonte de dados transformada possua mais de um registro retornado, todos os valores dos atributos "cod" serão retornados separados por vírgula. O código desse token igualmente não muda de ambiente para ambiente, sendo único e passível de ser configurado hard-coded.